Unicode
Unicode 是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的 Unicode 字符分为 17 组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有 65536 个码位,共 1114112 个。
它是方案而不是实际的数据格式,或者说它是一项标准而不是具体编码。旧版本的 Windows 记事本另存中有 Unicode 选项,实际上这里的 Unicode 指的是 UTF-16,一些别的软件中也可能是 UCS-2。也许是微软意识到叫 Unicode 不合适,所以 Win10 中改成了 UTF-16。UTF-32、UTF-16 、UTF-8、UCS-2 等都是 Unicode 编码的实现形式。
UTF-8
UTF(Unicode Transformation Format),通用转换格式。UTF-8 是针对 Unicode 的一种可变长度字符编码。它可以用来表示 Unicode 标准中的任何字符。UTF-8 使用 1 ~ 4 字节为每个字符编码,1 字节的 UTF-8 字符与 ASCII(7 位)是兼容的。
UTF-8 编码规则:如果只有一个字节则其最高二进制位为 0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为 1 的个数决定了其编码的字节数,其余各字节均以 10 开头。
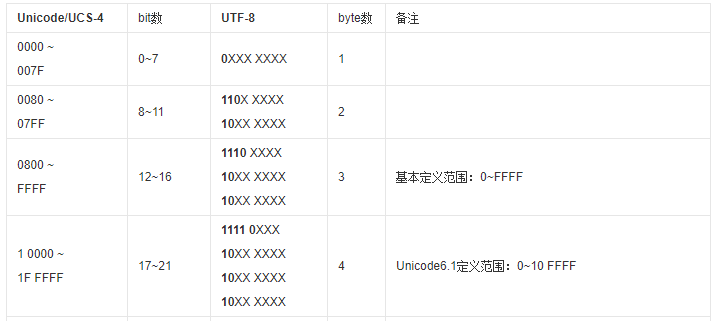
UTF-8 的编码方法决定了它是有字节序并且字节序是明确的。它是以字节为单位传输和处理的,所以不存在多字节数值大小端的问题。所以也就没有大小端的定义。因为是基于 8 位字节的,所以是 -8。
UTF-8 的特征决定了它适宜用于网络数据传输等业务(不用区分大小端字节序),不太适合做存储、字符串分析等(通过 UTF-8 的字节数不太容易得出实际的字符数量)。
UTF-16
UTF-16 比起 UTF-8,好处在于大部分字符都以固定长度的字节 (2 字节) 储存,但 UTF-16 却无法兼容于 ASCII 编码(因为 ASCII 也用两个字节)。在 Unicode 基本多文种平面定义的字符(无论是拉丁字母、汉字或其他文字或符号),一律使用 2 字节储存。而在辅助平面定义的字符,会以代理对(surrogate pair)的形式,以两个 2 字节的值来储存。所以 UTF-16 是两字节或 4 字节的。
UTF-16 与 UCS-2 的关系
UTF-16 可看成是 UCS-2 的父集。在基本多文种平面(Basic Multilingual Plane),UTF-16 与 UCS-2 是一致的,所以有的软件写的是 UCS-2,有的软件写的是 UTF-16,是一样的。但当引入辅助平面字符后,就称不一样了。
GB18030
兼容了 GBK、GB2312。
Latin1
Latin1 是 ISO-8859-1 的别名,有些环境下写作 Latin-1。ISO-8859-1 编码是单字节编码,向下兼容 ASCII,其编码范围是 0x00 - 0xFF,0x00 - 0x7F 之间完全和 ASCII 一致,0x80 - 0x9F 之间是控制字符,0xA0 - 0xFF 之间是文字符号。
QChar
封装了 16-bit Unicode 字符(UTF-16)。
QString
则是由 QChar 形成的字符串,所以 QString 所存储的字符串就是 UTF-16 编码的。
所以不要说某个 QString 字符串是 GBK 编码还是 UTF-8 编码,都不存在的,只能是 UTF-16 编码。
GBK 与 UTF-8 的转换只能在 QByteArray 之间转换,桥梁是 QString,而不是在 QString 之间转换。
小实验
QString str = "中文";
qDebug() << str;
qDebug() << qstr2hex(str, true); //utf-16 4E 2D 65 87
qDebug() << str.toUtf8().toHex(' ').toUpper(); //utf-8 E4 B8 AD E6 96 87
qDebug() << str.toLatin1().toHex(' ').toUpper(); //非Latin1,输出“??”
QTextCodec::setCodecForLocale(gbk);
qDebug() << str.toLocal8Bit().toHex(' ').toUpper(); //GBK D6 D0 CE C4
QTextCodec::setCodecForLocale(utf8);
qDebug() << str.toLocal8Bit().toHex(' ').toUpper(); //utf-8 E4 B8 AD E6 96 87
QTextCodec::setCodecForLocale(nullptr);
qDebug() << str.toLocal8Bit().toHex(' ').toUpper(); //默认gbk D6 D0 CE C4
输出:
"中文"
"4E 2D 65 87"
"E4 B8 AD E6 96 87"
"3F 3F"
"D6 D0 CE C4"
"E4 B8 AD E6 96 87"
"D6 D0 CE C4"


 发表于 2024-1-19 01:48:22
发表于 2024-1-19 01:48:22